JambaTalk: Speech-driven 3D Talking Head Generation based on Hybrid Transformer-Mamba Model
Abstract
In recent years, the talking head generation has become a focal point for researchers. Considerable effort is being made to refine lip-sync motion, capture expressive facial expressions, generate natural head poses, and achieve high video quality. However, no single model has yet achieved equivalence across all these metrics. This paper aims to animate a 3D face using Jamba, a hybrid Transformer-Mamba model. Mamba, a pioneering Structured State Space Model (SSM) architecture was developed to overcome the limitations of conventional Transformer architectures, particularly in handling long sequences. This challenge has constrained traditional models. Jamba merges the advantages of both the Transformer and Mamba approaches, providing a holistic solution. Based on the foundational Jamba block, we present JambaTalk to enhance motion variety and speed through multimodal integration. Extensive experiments reveal that our method achieves performance comparable to or superior to state-of-the-art models.
Proposed Method
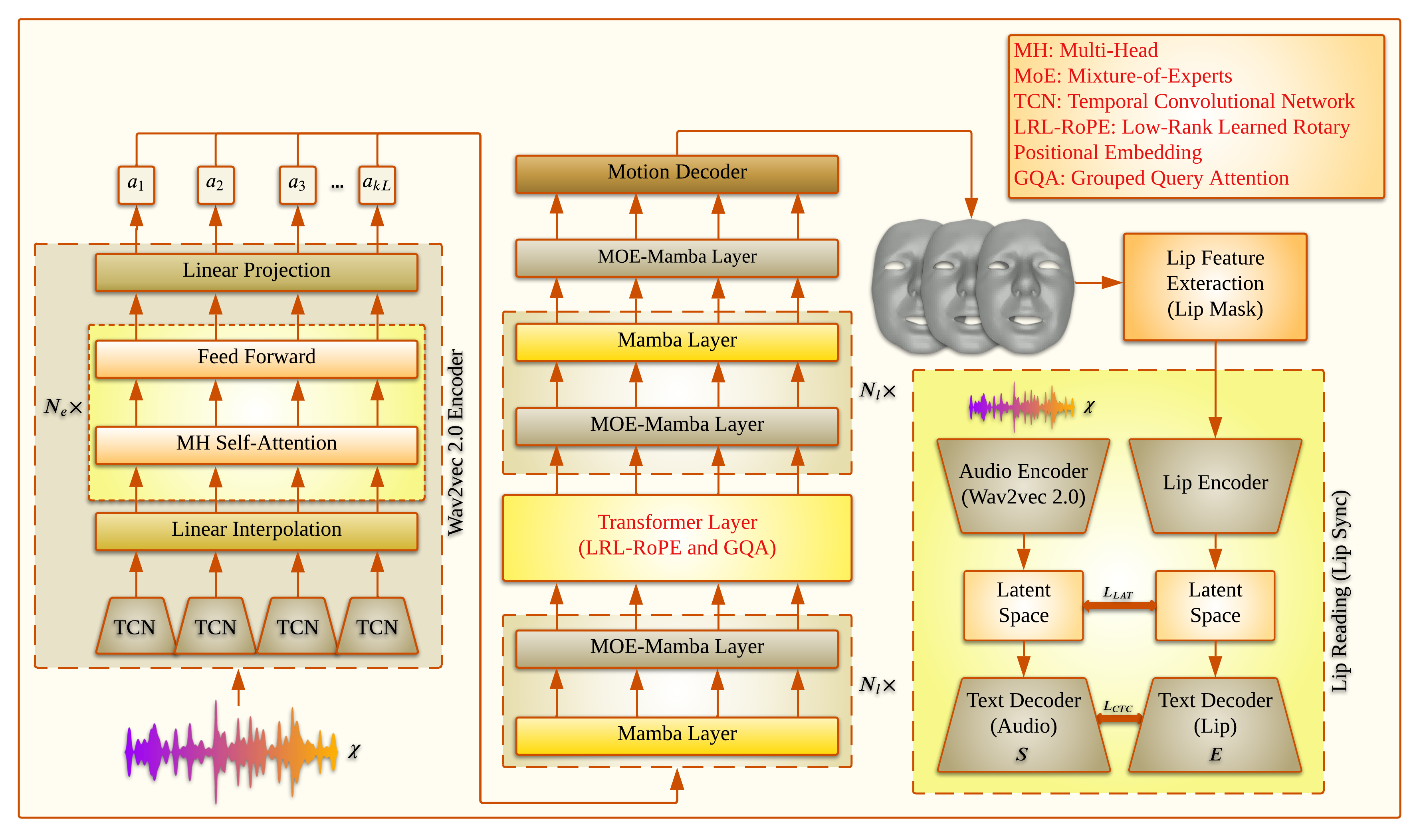
Real-time JambaTalk
Our real-time implementation of JambaTalk demonstrates the model's capability for interactive speech-driven facial animation. The system processes audio input in real-time and generates synchronized 3D facial movements with low latency, making it suitable for live applications such as virtual assistants, video conferencing, and interactive avatars.
BibTeX
@inproceedings{jambatalk2024Jafari,
title={JambaTalk: Speech-driven 3D Talking Head Generation based on a Hybrid Transformer-Mamba Model},
author={Farzaneh Jafari, Stefano Berretti, Anup Basu},
year={2024},
note={arXiv preprint arXiv:2408.01627}
}